Jun 20, 2023
Like many of you, we at be radical have been fascinated lately with thinking through the rippling implications of today’s (and tomorrow’s) LLMs – the large language model AIs that have captured both the collective imagination and a huge amount of investment recently.
One implication that I keep coming back to is what all of this could mean for software production in the next few years and then what all of that could mean for any number of businesses.
The key argument here (which I first heard sketched by Paul Kodrosky & Eric Norlin of SK Ventures) goes like this. In the past several decades, we’ve seen the cost of key technological inputs involved in digital innovation and software production collapse. The costs of computation, data storage, and networking have all declined dramatically – transformationally, even – making new things, including the creation of wildly valuable new digital products, services, and platforms possible.
But all the while, one other key factor has remained very scarce and very expensive – software engineers.
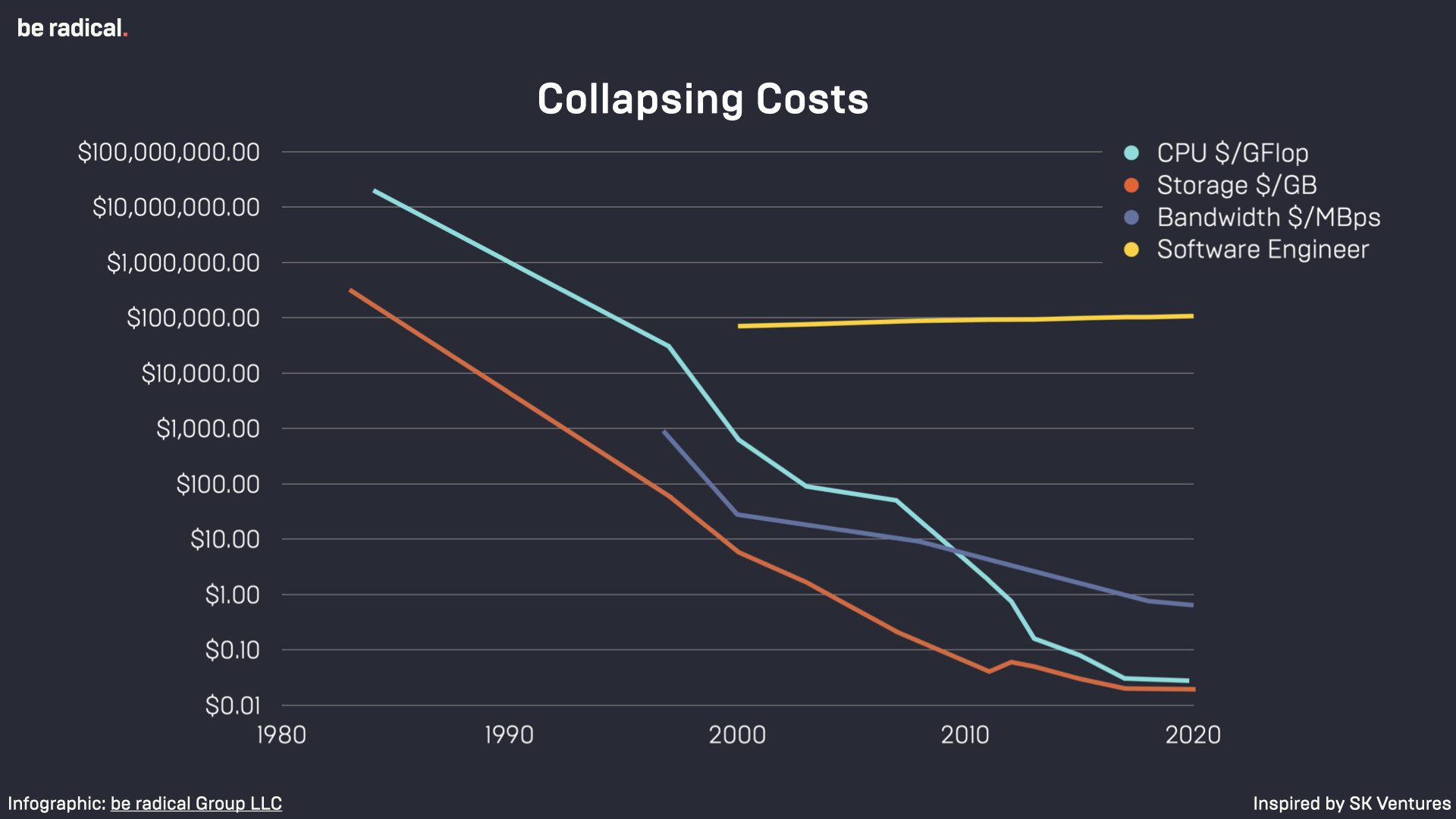
This picture may be about to shift significantly. Early studies suggest that programmers using new tools like GitHub Copilot (with the AI acting as a pair-programming partner) are reporting significant productivity increases.
Quite a bit of coding is the kind of thing (grammatical and predictable) that LLMs should be able to do very well in time. That should make aspects of software development cheaper and faster and easier to do. As Rodney Brooks, who is generally on the more skeptical end of the continuum regarding the potential of LLMs, has written: “It is going to be easier to build from scratch software stacks that look a lot like existing software stacks.”
That’s not nothing, friends. Existing, known tech stacks will become easier to reproduce. Development cycles will accelerate. Some barriers to entry will disappear.
There are many, many potential upshots here, but I’ll highlight just two for now. In this scenario, a couple of things will become more important than ever before for businesses of all types:
(via Jeffrey)